
多機能な PDF 編集ソフト!「ByteScout PDF Multitool」
ByteScout PDF Multitool
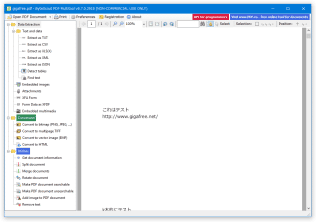
ByteScout PDF Multitool
PDF ファイルを、変換 / 分割 / 結合 / 回転 / 編集 することができる多機能ツール。
指定した PDF を TXT / CSV / HTML / XML / JSON / XLSX / PNG / JPEG / BMP / GIF / TIFF / EMF に変換したり、PDF を二つに分割したり、複数の PDF を一つに連結したりすることができます。
PDF 内の画像に記載されている文字列を OCR で読み取る機能や、PDF の特定領域に画像を合成する機能、PDF の特定領域内にある文字列を消去する機能、PDF 内のページを削除する機能 等も付いています。
「ByteScout PDF Multitool」は、多機能な PDF 編集ツールです。
- PDF を、TXT / CSV / HTML / XLSX / XML / JSON に変換※1
- PDF を、PNG / JPEG / BMP / GIF / TIFF(マルチページも可) / EMF に変換
- PDF 内の画像を抽出
- 複数の PDF ファイルを、一つに連結
- 指定したページを境にして、一つの PDF を二つに分割
- PDF を、右に 90 度 / 180 度 / 270 度 回転
- PDF 内のページを、範囲指定して抽出
- PDF 内のページを、範囲指定して削除
- PDF 内の文字列を OCR で読み取り、読み取り結果を元に PDF を再構成
(テキスト検索可能な PDF に変換) - PDF の内容を画像に変換し、変換結果の画像を元に PDF を再構成
(テキスト検索不可能な PDF に変換) - PDF 内の特定領域にある文字列を消去
- PDF 内の特定領域に画像を合成
1 日本語のテキストも変換できるが、精度は 70 ~ 80% くらいなので注意。
オープンソースの OCR エンジン「Tesseract」を使えるところもポイントの一つで、
- PDF 内の画像に記載されている文字列
- ベクター画像で構成された文字列
- スキャンなどが原因で、歪んでしまった文字列
(ただし、読み取り精度は元のデータによってまちまち)
普段、PDF を他の形式に変換したり、PDF 内のテキストや画像を抽出したりすることがよくある人におすすめです。
ちなみに、処理の際には、PDF 内の特定領域(マウスドラッグで指定した矩形領域)のみを処理対象として設定することもできたりします。
使い方は以下の通り。
- 準備
- 実際に使う
- PDF を、TXT / CSV / XLSX / XML / JSON に変換する
- PDF 内の画像を抽出する
- PDF を、PNG / JPEG / BMP / GIF / TIFF / EMF に変換する
- PDF のプロパティを表示する
- PDF の分割、ページの抽出・削除
- 複数の PDF を、一つに連結する
- PDF を回転する
- PDF の内容を OCR で読み取り、読み取り結果を元に PDF を再構成する
- PDF の内容を画像に変換し、変換された画像を元に PDF を再構成する
- PDF 内の特定部分に、画像を合成する
- PDF 内の特定領域内にあるテキストを、消去する
準備
- 前述のとおり、「ByteScout PDF Multitool」では
- PDF 内の画像に記載されている文字列
- ベクター画像で構成された文字列
- スキャンなどが原因で、歪んでしまった文字列
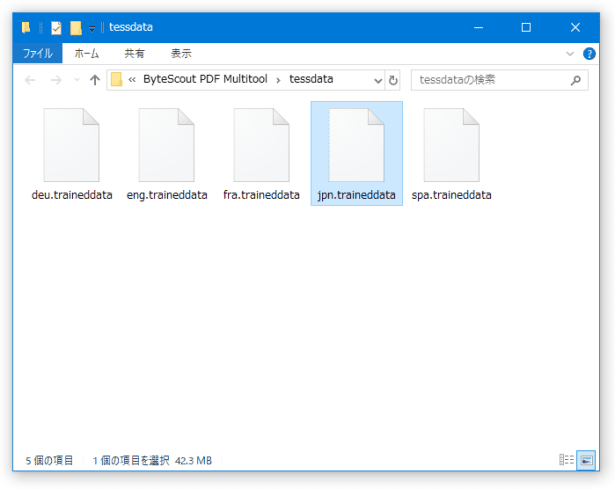
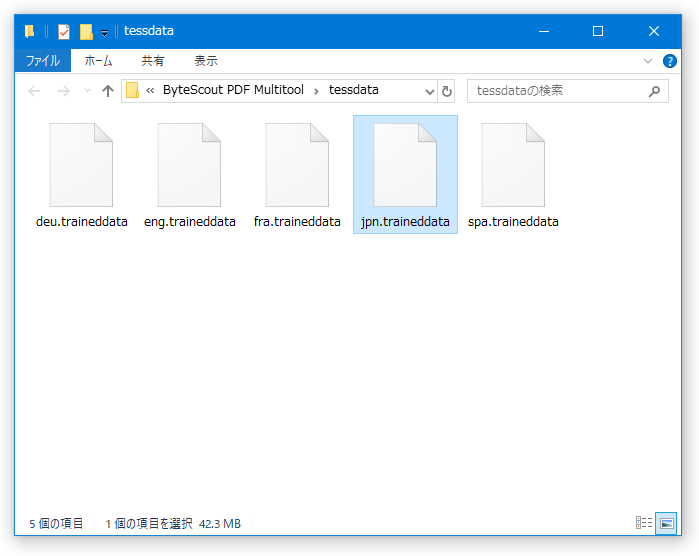
この OCR を使って日本語のテキストを読み取ることがありそうな場合は、事前に「jpn.traineddata」をダウンロードし、それをインストールフォルダ内にある「tessdata」フォルダ内にコピーしておきます。
実際に使う
- 「BytescoutPDFMultitool.exe」を実行します。
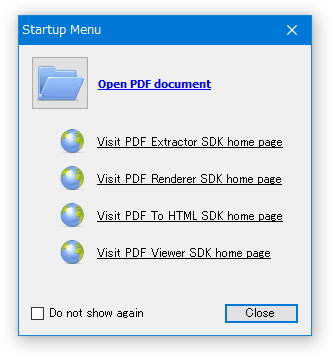
- 最初に「Startup Menu」というダイアログが表示されますが、これは「Close」ボタンを押して閉じてしまって OK です。
ダイアログの左下にある「Do not show again」にチェックを入れると、次回からこのダイアログが表示されなくなります。
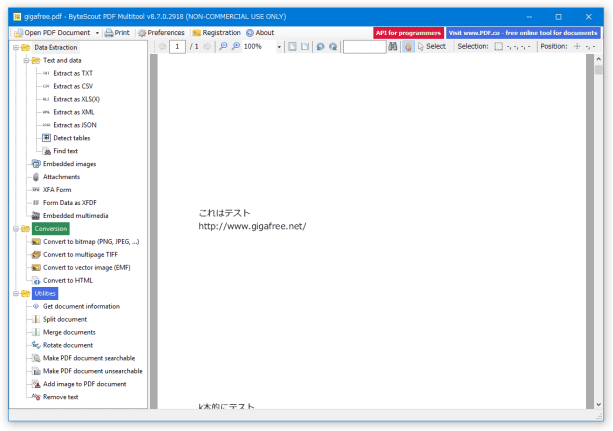
- メイン画面が表示されます。
そのまま、ツールバーの左端にある「Open PDF Document」ボタンをクリックし、編集したい PDF ファイルを読み込みます。
尚、ファイル読み込み時に下記のようなエラーが表示されることがあります。このダイアログが表示されると、それ以降 PDF を読み込めなくなってしまうようなので、「OK」ボタンを押して「ByteScout PDF Multitool」を再起動させてください。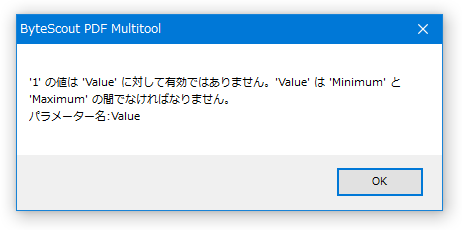
- 標準では、何らかの処理を行った後に
- 作成されたファイル
- 作成されたファイルの出力先フォルダ
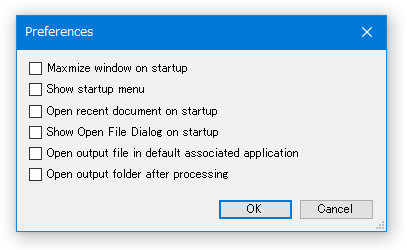
これらの挙動を変更したい時は、ツールバー上にある「Preferences」ボタンをクリックし、- Open output file in default associated application
処理完了後、作成されたファイルを関連付けソフトで開く - Open output folder after processing
処理完了後、作成されたファイルの出力先フォルダを自動で開く
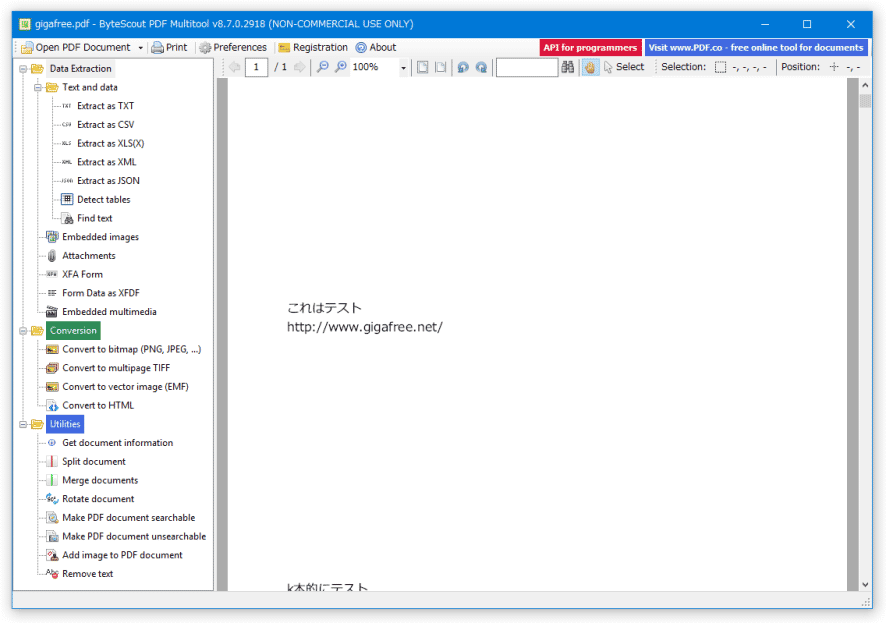
PDF を、TXT / CSV / XLSX / XML / JSON に変換する
- PDF 内の特定部分のみを変換したい時は、右ペインのツールバー上にある「Select」ボタンをクリック → 変換したい部分をドラッグして囲みます。
(選択の解除を行う時は、範囲選択した部分以外の領域をクリックする)2 ページ目以降を編集したい時は、右ペインのツールバー上にあるページネーションを使い、ページ移動を行っておきます。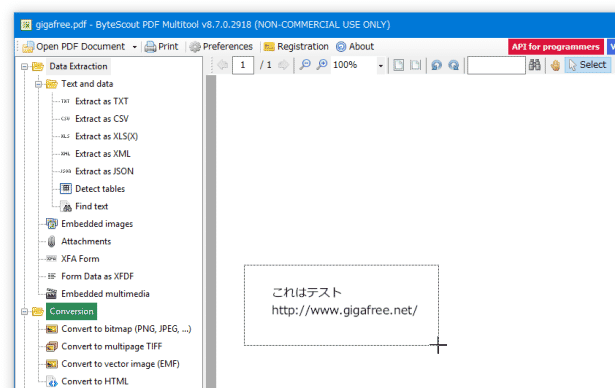
- 画面左側の「Text and data」ツリー配下にある
- Extract as TXT - PDF を、TXT ファイルに変換
- Extract as CSV - PDF を、CSV ファイルに変換
- Extract as XLS(X) - PDF を、XLSX ファイルに変換
- Extract as XML - PDF を、XML ファイルに変換
- Extract as JSON - PDF を、JSON ファイルに変換
- オプション画面が表示されます。
基本的にはデフォルトのままで OK ですが、
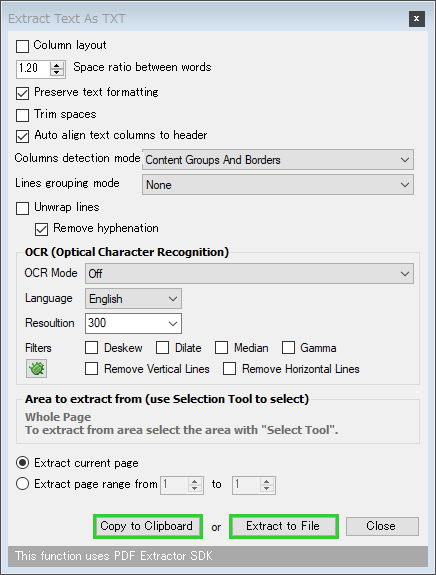
- 画像内のテキスト
- ベクター画像で構成された文字列
- スキャンなどが原因で、歪んでしまった文字列(OCR なしでは読み取れなかった文字列)
- OCR Mode - 読み取り対象
- Auto
自動 - Text From Images And Vectors And Fonts
画像内のテキスト、ベクター画像で構成されたテキスト、通常のテキスト - Text From Images And Vectors And Repaired Fonts
画像内のテキスト、ベクター画像で構成されたテキスト、スキャン等で歪んだテキスト - Text From Repaired Fonts Only
スキャン等で歪んだテキスト - Text From Images And Repaired Fonts
画像内のテキストと、スキャン等で歪んだテキスト - Text From Images And Fonts
画像内のテキストと、通常のテキスト - Text From Images Only
画像内のテキスト - Text From Images And Vectors Only
画像内のテキストと、ベクター画像で構成されたテキスト
- Auto
- Language - 読み取る文字列の言語
- Resoultion - テキスト読み取り時の解像度※2
2 数値が大きいほど読み取り精度が高くなるが、その分処理速度が遅くなる。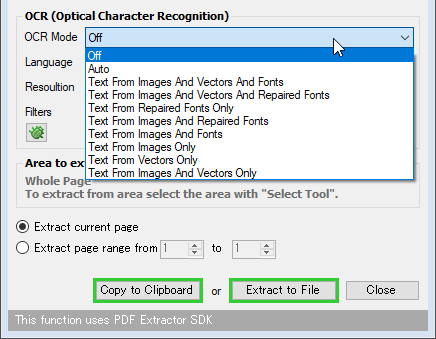
- 必要に応じて、一番下の欄で
- Extract current page - 現在表示中のページのみを変換する
- Extract page range from 〇 to △ - 〇ページから△ページまでを変換する
3 XLSX 以外に変換する時は、「Copy to Clipboard」(クリップボードにコピー)ボタンを使ってもよい。 - 「名前を付けて保存」ダイアログが立ち上がります。
あとは、変換されたファイルの出力先フォルダ&ファイル名 を指定すれば OK です。
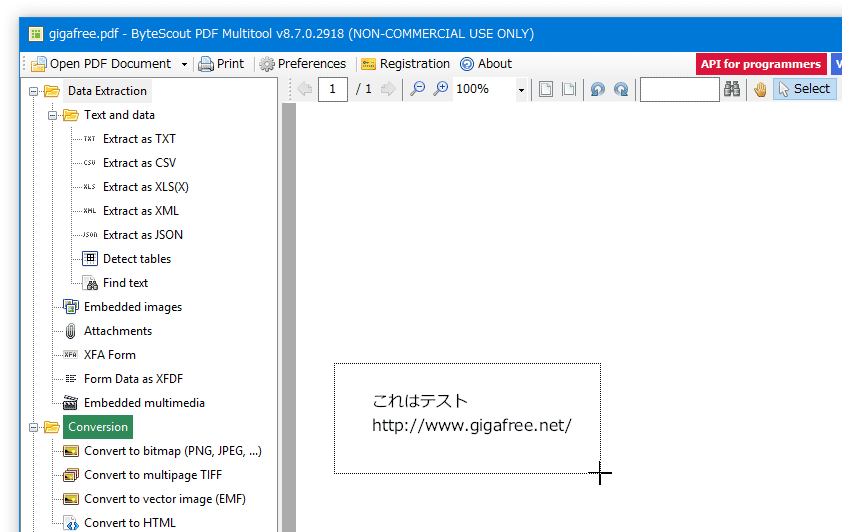
PDF 内の画像を抽出する
- 画面左側の「Data Extraction」ツリー配下にある「Embedded images」を選択します。
- 「Extract Embedded Images」というダイアログが表示されます。
まず、一番上の「Output image format」欄で、抽出された画像の出力フォーマットを選択します。
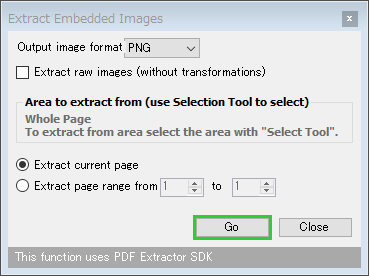
画像をオリジナル形式のまま出力したい時は、「Extract raw images (without transformations)」にチェックを入れておきます。 - 現在表示しているページからのみ抽出を行う時は、「Extract current page」にチェックを入れます。
指定した範囲内のページから抽出を行う場合は、「Extract page range from 〇 to △」にチェック → 抽出を行うページの先頭番号と末尾の番号を指定します。 - 準備が整ったら、画面右下にある「Go」ボタンをクリック。
- 「フォルダーの参照」ダイアログが表示されます。
あとは、抽出された画像の保存先フォルダを指定すれば OK です。
次のページでは、
- PDF を、PNG / JPEG / BMP / GIF / TIFF / EMF に変換する方法
- PDF のプロパティを表示する方法
- 一つの PDF を、二つに分割する方法
- PDF 内の特定ページを抽出・削除 する方法
- 複数の PDF を、一つに連結する方法
- PDF を回転する方法
- PDF の内容を OCR で読み取り、読み取り結果を元に PDF を再構成する方法
(テキスト検索可能な PDF に変換) - PDF の内容を画像に変換し、変換された画像を元に PDF を再構成する方法
(テキスト検索不可能な PDF に変換) - PDF 内の特定部分に、画像を合成する方法
- PDF 内の特定文字列を、消去する方法

| PDF Eraser TOPへ |
アップデートなど
別館

最近は Chrome 拡張機能や Firefox アドオンの紹介が多め...
おすすめフリーソフト
新着フリーソフト
おすすめフリーソフト
スポンサードリンク