
多機能な PDF 編集&変換ソフト!「PDF Shaper」。

PDF Shaper
多機能な PDF 編集&変換ソフト。
PDF を TXT ファイルや画像ファイルに変換する機能、PDF 内のテキスト / 画像 / ページ を抽出する機能、複数の PDF を一つに結合する機能、PDF を指定した個数に分割する機能、PDF を回転する機能、PDF をトリミングする機能、PDF 内の特定ページを削除する機能、PDF 内の画像を削除する機能、PDF のセキュリティ設定を解除する機能、PDF のメタデータを編集する機能... 等々が付いています。
PDF Shaperは、多機能な PDF 編集ソフトです。
- PDF を TXT ファイルに変換
- PDF を画像ファイル(BMP / JPEG / WMF / EMF / EPS / PNG / GIF / TIFF)に変換
- 画像ファイル(BMP / JPEG / WMF / EMF / PNG / GIF / TIFF)を PDF に変換
- PDF 内のテキストを抽出
- PDF 内の画像を一括して抽出
- PDF 内の特定ページを抽出
- PDF 内の特定ページを削除
- PDF 内の画像を一括して削除
- PDF のセキュリティ設定を解除する
- PDF のメタデータを編集
- 複数の PDF を一つに結合
- PDF を指定した個数、または指定したページごとに分割
- PDF を回転
- PDF をトリミング
基本的には、処理したい PDF をドラッグ&ドロップ → 実行したいアクションを選択する だけで使うことができるので、面倒な手順を踏むことなく手早く使うことができます。
普段、PDF をあれこれ編集したりする機会が多い人におすすめです。
ちなみに、複数の PDF をまとめて編集できるのはもちろん、PDF の入ったフォルダごと処理することも可能となっています。
基本的な使い方は以下のとおりです。
- インストール時の注意
- 使用上の注意
- 日本語化
- 処理するファイルを登録する
- PDF を TXT ファイルに変換する
- PDF を画像ファイルに変換する
- 画像ファイルを PDF に変換する
- PDF 内のテキストを抽出する
- PDF 内の画像を一括抽出する
- PDF 内の特定ページを抽出する
- PDF 内の特定ページを削除する
- PDF 内の画像を削除する
- PDF のセキュリティを解除する
- PDF のメタデータを編集する
- 複数の PDF を一つに結合する
- PDF を指定した個数、または指定したページごとに分割
- PDF を回転する
- PDF をトリミングする
インストール時の注意
- インストールの途中で「P2P ネットワークに参加する」というような画面が表示されますが、参加は必須ではありません。
「Join Infatica peer-to-peer network」のチェックを外してから「Next」ボタンをクリックしてください。また、バージョンによっては、外部ツールのインストールを促す画面が表示されることもあります。
 このような画面が表示されたら、右下にある「Decline(拒否する)」ボタンをクリックしてください。
このような画面が表示されたら、右下にある「Decline(拒否する)」ボタンをクリックしてください。
使用上の注意
- 選択時に「This option is available in Premium and Pro editions only!」というダイアログが表示される機能は、有料版のみの機能となっています。
「はい」を選択すると有料版のダウンロードページが表示されるので、無料版を使い続ける場合は「いいえ」を選択してください。

日本語化
- 「PDF Shaper」が実行中である場合は、一旦終了させておきます。
- DONKICHIROU さんのサイト で、「PDF Shaper」の日本語ランゲージファイルを入手し、解凍 しておきます。
- 解凍して出てきた「Japanese.lng」を、「PDF Shaper」のインストールフォルダ内にコピーします。


処理するファイルを登録する
- 「PDFShaper.exe」を実行します。
- メイン画面が表示されます。
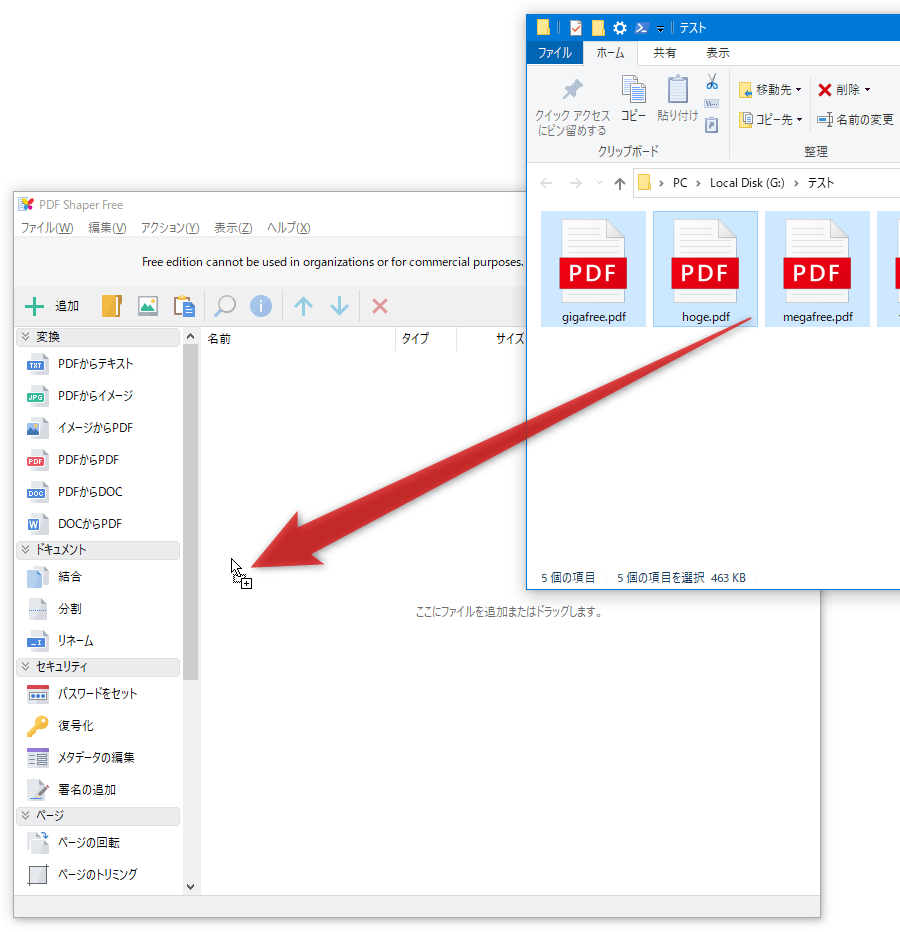
ここに、処理したい PDF ファイルをドラッグ&ドロップします。

(処理したい PDF が入ったフォルダごとドロップすることもできます)画像ファイルを PDF に変換する時は、目的の画像ファイルをドラッグ&ドロップします。
(処理したい画像ファイルが入ったフォルダごとドロップすることもできます)
- ドロップした PDF にパスワードがかかっていると「パスワード」というダイアログが表示されるので、「パスワードを入力してください」欄に PDF のパスワードを入力して「OK」ボタンをクリックします。
この時、「すべてのファイルにパスワードを適用する」にチェックを入れておくと、他の保護されたファイルに対しても同一のパスワードを適用することができたりします。

- ドラッグ&ドロップしたファイルが、リストに登録されました。
ファイルを間違えて登録してしまった時は、ファイルリスト上で該当のファイルを選択 → ツールバー上にある
 ボタンをクリックします。
ボタンをクリックします。



PDF を TXT ファイルに変換する
- 画面左側の「変換」メニュー内にある「PDF からテキスト」を選択します。
- 「PDF からテキスト」という画面が表示されます。
ここで、

- テキストのレイアウトを維持するかどうか
- ページ番号 - 出力する TXT ファイル内に、ページ番号を付加する
- ページ
- すべてのページを処理する
- Process first page - 1 ページ目のみを変換する
- Process last page - 最後のページのみを変換する
- 選択したページを処理する※1

1 連続したページ番号を指定する時はハイフンを、連続していないページ番号を指定する時はカンマを使う。
たとえば、1 ページ目 / 2 ページ目 / 4 ページ目 を変換したい時は、“ 1-2,4 ” のように入力する。
- 複数のファイルを処理する時は「フォルダーの参照」というダイアログが、単一のファイルを処理する時は「名前を付けて保存」ダイアログ表示されます。
 ここで、変換された TXT ファイルの出力先フォルダやファイル名を指定し、右下の「OK」ボタンや「保存」ボタンをクリックします。
ここで、変換された TXT ファイルの出力先フォルダやファイル名を指定し、右下の「OK」ボタンや「保存」ボタンをクリックします。
- 少し待ち、「Process completed successfully」という画面が表示されたら変換完了です。
画面右下の「進む」ボタンをクリックすると、メイン画面に戻ることができます。

(「開く」ボタンをクリックすると、出力先のフォルダや出力されたファイルを開くことができる)

PDF を画像ファイルに変換する
- 画面左側の「変換」メニュー内にある「PDF からイメージ」を選択します。
- 「PDF からイメージ」という画面が表示されます。
ここで、

- イメージフォーマット - 変換先のフォーマット

- イメージ解像度 - 出力画像の解像度

- ページ
- すべてのページを処理する
- Process first page - 1 ページ目のみを変換する
- Process last page - 最後のページのみを変換する
- 選択したページを処理する※1
- 奇数ページを処理する
- 偶数ページを処理する
1 連続したページ番号を指定する時はハイフンを、連続していないページ番号を指定する時はカンマを使う。
たとえば、1 ページ目 / 2 ページ目 / 4 ページ目 を変換したい時は、“ 1-2,4 ” のように入力する。 - イメージフォーマット - 変換先のフォーマット
- 「フォルダーの参照」というダイアログが表示されます。
ここで、変換された画像ファイルの出力先フォルダを選択し、画面右下にある「OK」ボタンをクリックします。
- 少し待ち、「Process completed successfully」という画面が表示されたら変換完了です。
画面右下の「進む」ボタンをクリックすると、メイン画面に戻ることができます。

(「開く」ボタンをクリックすると、出力先のフォルダや出力されたファイルを開くことができる)
画像ファイルを PDF に変換する
- 画面左側の「変換」メニュー内にある「イメージから PDF」を選択します。
- 「イメージから PDF」という画面が表示されます。
ここで、

- 画像のサイズ
- オリジナルのサイズを保持する
- ページサイズに伸縮
- ページに合わせる(縦横比を保持)

- Ignore DPI value - DPI を無視する
- 水平方向中央 - 画像の揃え位置
- 垂直方向中央 - 画像の揃え位置
- ページサイズ - A4 / A5 / A3 / B5 等
- ランドスケープレイアウト - 横向きの PDF にする
- 各画像を個別のファイルとして保存する
- メタデータ
- ドキュメント情報を追加する

- 画像のサイズ
- 「名前を付けて保存」ダイアログが立ち上がります。
ここで、変換された PDF ファイルの出力先フォルダ&ファイル名 を設定し、画面右下にある「保存」ボタンをクリックします。

尚、オプション画面で「各画像を個別のファイルとして保存する」にチェックを入れていた場合は、「フォルダーの参照」ダイアログが表示されるので、変換されたファイルの出力先フォルダを選択して「OK」ボタンをクリックします。
- 少し待ち、「Process completed successfully」という画面が表示されたら変換完了です。
画面右下の「進む」ボタンをクリックすると、メイン画面に戻ることができます。

(「開く」ボタンをクリックすると、出力先のフォルダや出力されたファイルを開くことができる)

PDF 内のテキストを抽出する
- ファイルリスト上でテキストの抽出を行いたいファイルを選択状態にし※2、画面左側の「抽出」メニュー内にある「テキストの抽出」を選択します。
2 複数のファイルをまとめて処理することはできない模様。 - 「テキストの抽出」という画面が表示されます。
ここに、選択していた PDF 内のテキストがプレーンテキスト化して表示されるので、必要な部分を選択してコピーしたりすれば OK です。

画面右下にある「保存」ボタンをクリックすることで、抽出されたテキストを TXT ファイルに保存することもできたりします。

PDF 内の画像を一括抽出する
- 画面左側の「抽出」メニュー内にある「イメージの抽出」を選択します。
- 「フォルダーの参照」というダイアログが表示されます。
そのまま、抽出された画像ファイルの出力先フォルダを選択し、画面右下にある「OK」ボタンをクリックします。
- 少し待ち、「Process completed successfully」という画面が表示されたら抽出完了です。
画面右下の「進む」ボタンをクリックすると、メイン画面に戻ることができます。

(「開く」ボタンをクリックすると、出力先のフォルダや出力されたファイルを開くことができる)
PDF 内の特定ページを抽出する
- 画面左側の「抽出」メニュー内にある「ページの抽出」を選択します。
- 「ページの抽出」という画面が表示されます。
ここで、

- 各ページを個別のファイルとして保存する
- ページを1つのドキュメントに結合する - 抽出したページを、一つの PDF として結合
- ページ
- すべてのページを抽出
- 最初のページを抽出する
- 最後のページを抽出する
- 選択したページを抽出※1
- 奇数ページを抽出
- 偶数ページを抽出

1 連続したページ番号を指定する時はハイフンを、連続していないページ番号を指定する時はカンマを使う。
たとえば、1 ページ目 / 2 ページ目 / 4 ページ目 を抽出したい時は、“ 1-2,4 ” のように入力する。 - 「フォルダーの参照」というダイアログが表示されます。
そのまま、抽出されたページの出力先フォルダを選択し、画面右下にある「OK」ボタンをクリックします。
- 抽出が完了すると、「Process completed successfully」と表示されます。
画面右下の「進む」ボタンをクリックすると、メイン画面に戻ることができます。

(「開く」ボタンをクリックすると、出力先のフォルダや出力されたファイルを開くことができる)
PDF 内の特定ページを削除する
- 画面左側の「削除」メニュー内にある「ページの削除」を選択します。
- 「ページの削除」という画面が表示されます。
ここで、

- ページ
- 先頭ページを削除
- 最終ページを削除
- 選択したページを削除※1
- 奇数ページを削除する
- 偶数ページを削除する

- メタデータ
- ドキュメント情報を追加する

1 連続したページ番号を指定する時はハイフンを、連続していないページ番号を指定する時はカンマを使う。
たとえば、2 ページ目 / 3 ページ目 / 7 ページ目 を削除したい時は、“ 2-3,7 ” のように入力する。 - ページ
- 複数のファイルを処理する時は「フォルダーの参照」というダイアログが、単一のファイルを処理する時は「名前を付けて保存」ダイアログ表示されます。
ここで、編集された PDF ファイルの出力先フォルダやファイル名を指定し、右下の「OK」ボタンや「保存」ボタンをクリックします。
- 少し待ち、「Process completed successfully」という画面が表示されたら処理完了です。
画面右下の「進む」ボタンをクリックすると、メイン画面に戻ることができます。

(「開く」ボタンをクリックすると、出力先のフォルダや出力されたファイルを開くことができる)
次のページでは、
- PDF 内の画像を削除する方法
- PDF のセキュリティを解除する方法
- PDF のメタデータを編集する方法
- 複数の PDF を一つに結合する方法
- PDF を指定した個数に分割する方法
- PDF を回転する方法
- PDF をトリミングする方法

| PDF Shaper TOPへ |
アップデートなど
別館

最近は Chrome 拡張機能や Firefox アドオンの紹介が多め...
おすすめフリーソフト

新着フリーソフト
スポンサード リンク
おすすめフリーソフト
スポンサードリンク